
实验任务要求
任务一
使用本实验给出的数据集,或者在网上下载感兴趣的数据集(Kaggle等),先对数据进行适当的预处理,然后使用线性回归(可使用sklearn等库函数实现)的方式拟合数据,并可视化结果。
任务二
根据任务一的数据,随机生成一些离群点(随机种子为自己学号的后两位数字),尝试使用不同正则化方式(L1正则、L2正则等)、不同的损失函数(平方误差、绝对误差等),进行数据点的拟合,找到更好的线性回归模型以及超参数设置。并对实验过程和结果进行相关分析。
任务三
利用线性回归方法进行应用创新。调研线性回归相关文献,谈一谈如何利用线性回归进行特征选择。
实验环境和数据准备

实验软件环境:VScode平台
实验版本:Python、Anacode3
实验实现
任务一
- 数据加载
- 数据预处理(归一化)
- 线性回归
引入panda包读取数据集regress_data2.csv,数据预处理。
将特征值选取为rooms和area,利用fill函数补全缺失。归一化特征:使用 StandardScaler 将特征数据标准化,转换为均值为0,标准差为1的分布
1 | data = pd.read_csv('H://lab//data//regress_data2.csv') |
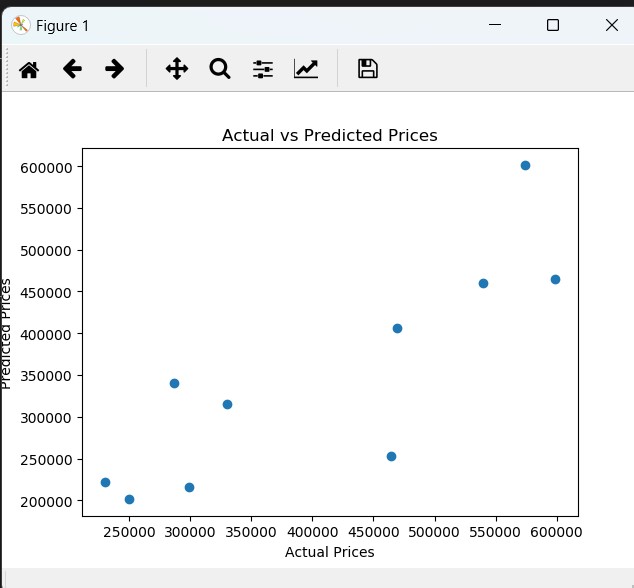
首先将数据集划分为训练集和测试集,采取0.2测试集的划分,random_states随便取值。开始训练并输出MSE和MAE,并利用matplotlib画图
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
任务二
离群点生成
随机种子取为学号后两位,生成5%离群点
1 | np.random.seed(76) |
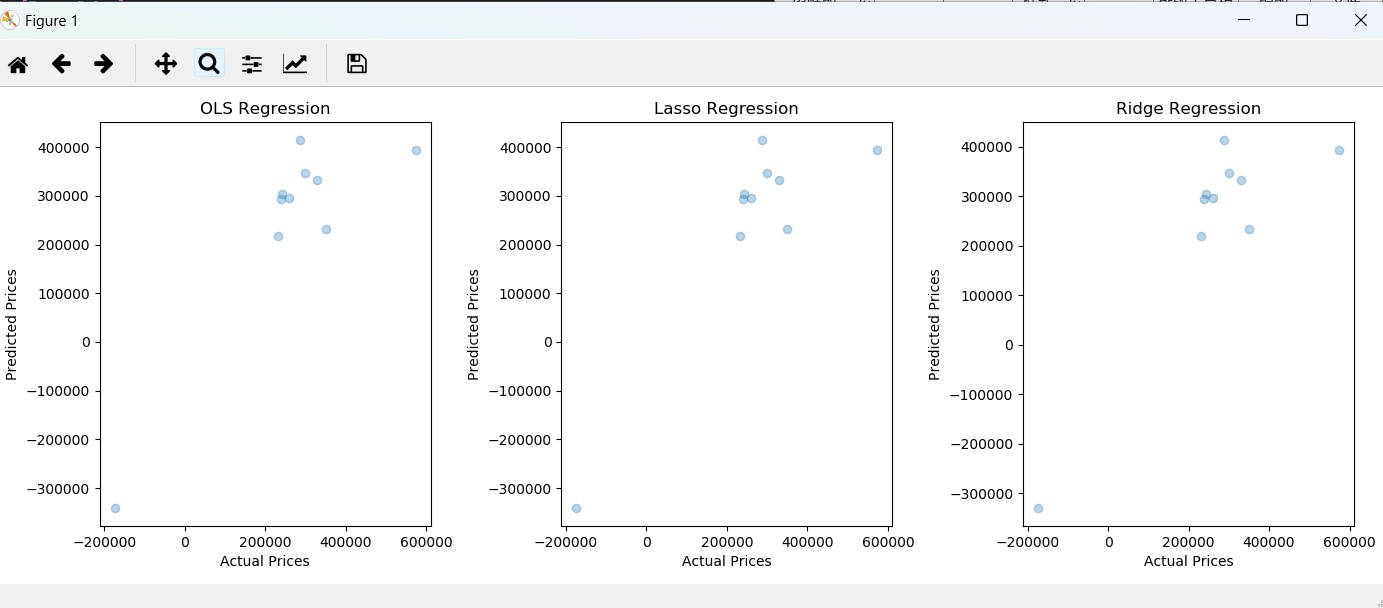
正则方法对比
用最小二乘、Lasso回归(L1正则)和Ridge回归(L2正则)来拟合数据,并评估其性能
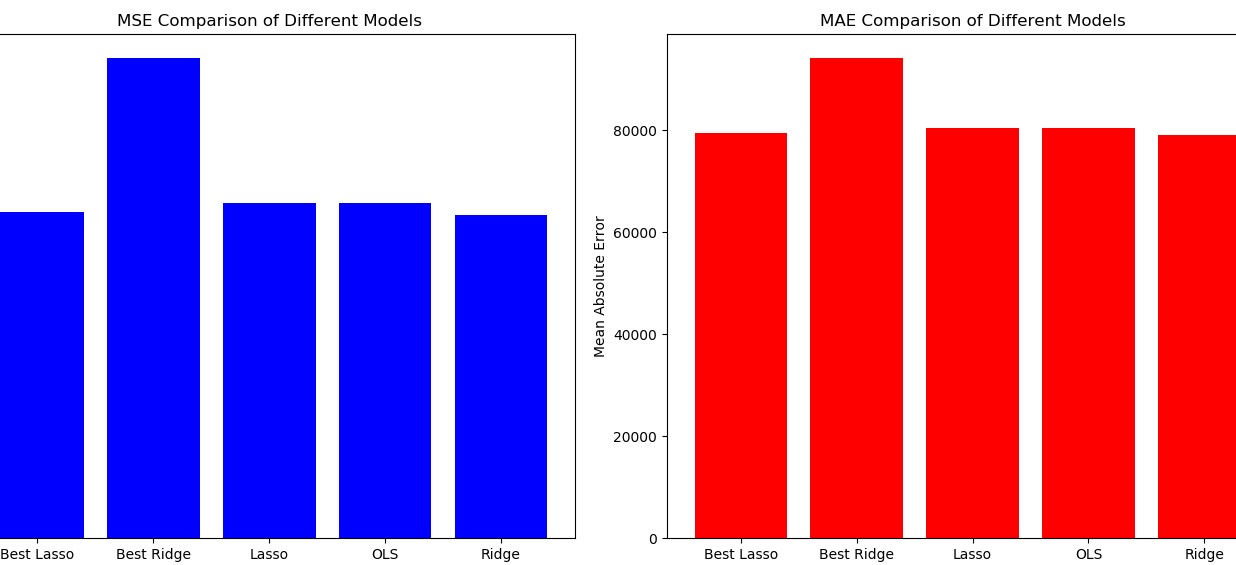
损失函数对比
MSE、MAE等
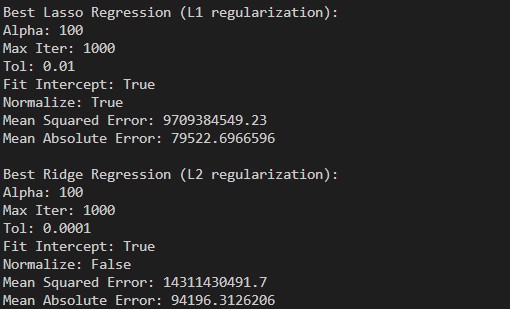
超参数选择对比
通过网格搜索(GridSearchCV)来调整Lasso和Ridge回归的超参数,找到最佳的超参数设置,并输出合适的超参数
1 |
|
实验结果展示
对上述实验过程和结果中的关键图表进行可视化展示,如线性回归的拟合线与样本分布的可视化、不同参数对比的损失值等。对实验过程和结果进行相关分析
实验结果分析
结果分析:Ridge的效果最好
Ridge回归通过L2正则化方法有效减少了过拟合,表现出更好的稳定性和泛化能力。这是因为L2正则化在缩小系数的同时,不会完全去除特征,因此能更好地处理多重共线性问题。Lasso回归适用于特征选择,但在本实验中,其性能略逊于Ridge回归。Lasso回归的L1正则化可以将某些特征系数缩小为零,从而进行特征选择,但可能导致模型在处理复杂数据
Ridge回归的调优结果未显著提升,可能与参数选择不当或数据集特性有关。需要进一步优化参数选择方法,如网格搜索或随机搜索,以找到更适合的数据集的超参数
实验拓展和创新
特征选择是机器学习和数据挖掘中的一个关键问题,尤其在处理高维数据时尤为重要。特征选择的目标是从大量的特征中挑选出对预测结果最有影响力的特征,从而提高模型的性能、降低计算成本并减少过拟合。在高维数据集中,很多特征可能是冗余的或无关紧要的,这不仅会增加计算复杂度,还会影响模型的预测能力。因此,有效的特征选择方法对于构建高性能模型至关重要。
Jiaqi Wang等人在2023年的研究《Carousel Greedy Algorithms for Feature Selection in Linear Regression》中提出了一种旋转贪婪算法,用于线性回归中的特征选择。该算法结合了贪婪算法和旋转机制,通过反复选择和调整特征来优化模型性能。贪婪算法在每一步选择当前最优的特征,而旋转机制则通过交替选择和丢弃特征来避免局部最优解,从而在全局范围内优化模型。
这种方法的优点在于其计算效率高,能够在大规模数据集中快速选择特征。此外,旋转贪婪算法能够有效处理特征间的相关性,避免冗余特征的选择,从而提高模型的解释性和预测能力。
具体应用
- 提高模型性能:
通过选择与目标变量最相关的特征,特征选择能够显著提高模型的预测性能。在实际应用中,许多数据集都存在大量无关或冗余的特征,这些特征不仅增加了计算成本,还可能引入噪声,影响模型的准确性。通过旋转贪婪算法,可以有效剔除这些无关特征,仅保留对模型有贡献的特征,从而提高预测精度。 - 减少计算成本:
高维数据集的计算成本往往非常高,特征选择通过减少特征数量,能够大大降低计算复杂度。在大规模数据分析和实时预测中,计算效率尤为重要。旋转贪婪算法通过高效的特征选择机制,能够在保证模型性能的同时,显著降低计算成本,适用于大数据分析和实时应用场景。 - 增强模型解释性:
在许多应用中,模型的可解释性非常重要,尤其在金融、医疗等领域,模型的决策依据需要透明且易于理解。通过特征选择,可以构建简洁而易于解释的模型,使得模型的预测结果更具说服力。旋转贪婪算法在选择特征时,考虑了特征的相关性和贡献度,从而构建出更加简洁和解释性强的模型。 - 处理高维数据:
高维数据集中的特征往往数量庞大且存在冗余,传统的特征选择方法在处理高维数据时可能表现不佳。旋转贪婪算法通过其独特的旋转机制,能够有效处理高维数据中的冗余特征,选择出对模型有最大贡献的特征,提高模型在高维数据集上的表现。
尽管旋转贪婪算法在特征选择中表现出色,但仍有一些改进空间。首先,可以结合其他特征选择方法,如嵌入式方法和过滤方法,进一步提高特征选择的准确性和稳定性。其次,可以结合深度学习技术,利用深度学习模型的特征提取能力,进一步提升特征选择的效果。最后,可以通过优化旋转机制,进一步提高算法的计算效率和选择效率。